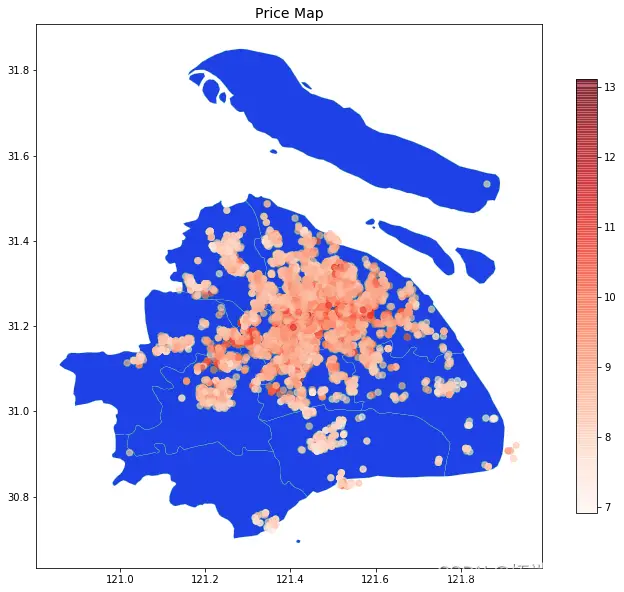
租房问题我们时常遇到,如今数据挖掘技术给租赁市场带来了新变化。那么,不同地区的租房数据挖掘究竟能给咱们带来什么好处?下面我们就来深入了解一番。
数据获取
针对北京短租房的研究,学者们聚焦于Airbnb平台。2019年4月17日,他们收集了北京区域的多种公开信息,包括房源基本信息、租赁时间表、用户评价以及行政区划资料等。而身处上海的他们,则运用Python技术,从链家网站的.csv文件中提取了租赁数据,为深入分析奠定了数据基础。
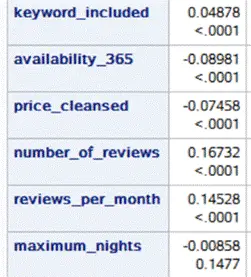
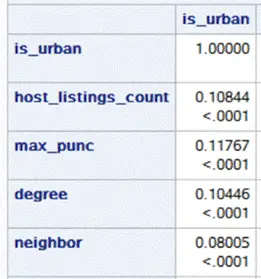
变量处理
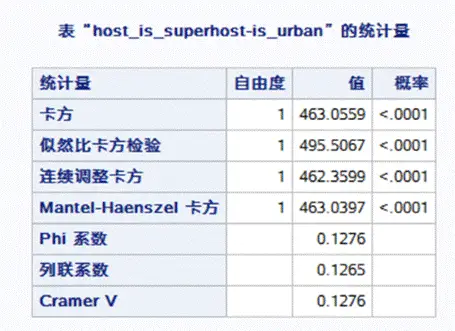
研究将所有变量划分成离散和连续两类。分别对这两类变量运用不同技术进行市区相关性的检测。同时,将市郊房型以虚拟变量形式展现。房东回应时长、房间种类、房源位置准确性,以及房东是否为高级房东等因素,也都逐一用虚拟变量替换,以方便模型构建。
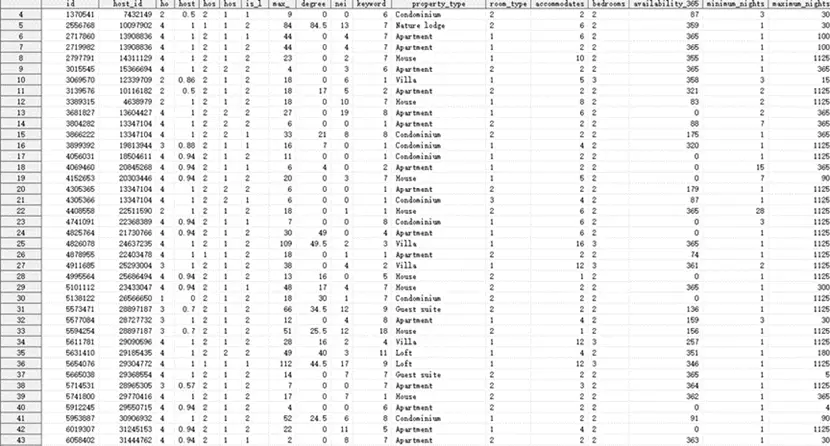
特征转换
该研究对房源的具体评分进行了转换处理。考虑到每项评分最高为10分,共有6项评分,为了使这些评分与总分review_scores_rating(满分100分)的量纲相匹配,我们将每个评分乘以权重10/6,从而得到新的变量review_scores_specific。这种转换使得数据在模型运算中能更有效地发挥作用。
模型构建

在建立模型的过程中,我们采用逻辑回归和决策树两种方法。在决策树模型中,内部节点用于记录分类特征,分支表示判断结果,而叶子节点则代表最终的分类。此外,我们将评分超过98.5的标记为1,低于98.5的标记为0,这些标记构成了目标变量score_kind。从根节点到叶子节点,形成了一套分类规则。另一方面,我们使用了上海链家提供的租房数据,构建了多种模型,包括岭回归、Lasso回归、随机森林、XGBoost、Keras神经网络以及kmeans聚类等。
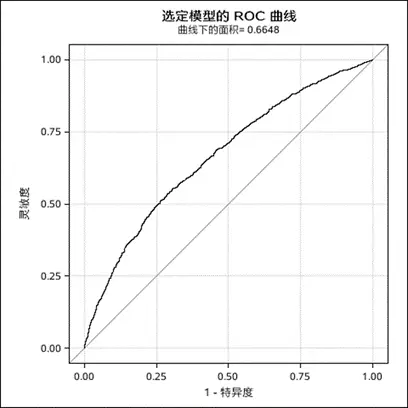
模型优化
模型优化确实有具体做法。比如在逻辑回归过程中,会把各个残差的统计数据导出到res_out数据集中,然后挑选出那些Pearson残差绝对值超过2的观测值作为异常数据。这样的筛选可以提升模型的准确度和可信度,从而使模型在实际应用中发挥更佳效果。
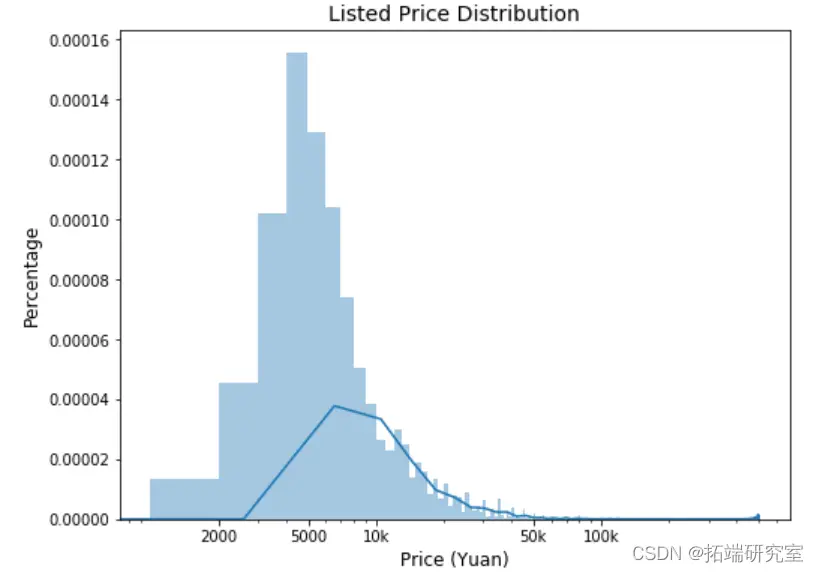
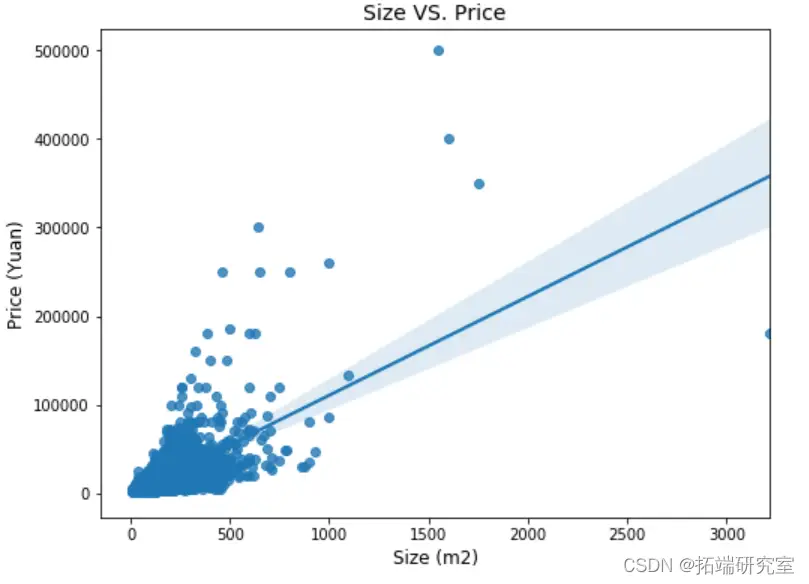
预测效果
预测结果显示,在城区数据分类中,决策树法准确率高达76.457%,而在郊区数据分类中,准确率更是达到了85.08%。这一结果充分显示出决策树在处理租房数据分类预测方面的优势,为短租房市场的精准运营和租房价格的合理预估提供了有力的数据支持。
观察这些数据挖掘所得,你认为在未来的租房市场里,哪个模型可能扮演更重要的角色?欢迎在评论区发表你的看法,同时别忘了点赞并转发这篇文章!